
I install Stable Audio Open on my PC because it allows me to create music with text.
What is Stable Audio Open?
Stable Audio Open is an open source AI model that can generate up to 47 seconds of audio samples and sound effects from text prompts. Using this model, you can create drum beats, instrument riffs, ambient sounds, Foley, and many other audio elements needed for sound production.
Key Features and Benefits
- Generation from Text Prompts: Generate audio samples and sound effects by simply entering simple text prompts.
- Versatile audio effects: Create drum beats, instrument riffs, ambient sounds, Foley, and many other sound effects.
- Audio variations and style transfers: Easily create variations of the generated audio or convert it to different styles.
- Fine-tuning with custom audio data: You can use your own audio data to fine-tune models and generate sounds that better suit your individual needs.
HOW TO USE
Stable Audio Open is widely used in music and sound design. For example, drummers can tweak their own drum recordings to create new beats, or filmmakers can generate their own sound effects to enhance the sound of their films.
Differences from Stable Audio
Stable Audio is a commercial product that allows users to create high-quality full tracks with a consistent musical structure up to 3 minutes in length. It also offers advanced features such as audio-to-audio generation and multipart composition. Stable Audio Open, on the other hand, is specialized for generating short audio samples and sound effects and is not optimized for full songs, melodies, or vocals.
Training Data and Ethical Considerations
Stable Audio Open’s models are trained using data from FreeSound and the Free Music Archive. This allows us to provide open audio models while respecting the rights of their creators.
Is it available for free?
With the release of Stable Audio 2, Stable Audio Open (version 1) is now available for free; you can download the weights of the model at Hugging Face and use them freely.
The following GitHubs are available to work with: the official GitHub of Stable Audio Open and the Docker-enabled GitHub page.

If you check the requirements, you will find the following
Requires PyTorch 2.0 or later for Flash Attention support
Development for the repo is done in Python 3.8.10
I tested the Docker version of Stable Audio Open on the GitHub page and it works.
No module named ‘flash_attn’
flash_attn not installed, disabling Flash Attention

It means that either PyTorch 2.0 or later and Python 3.8.10 are required. This error message indicates that flash_attn is not installed, disabling its functionality. However, if you do not use the flash_attn feature, this can be safely ignored.
If you want to use the flash_attn feature, you will need to install its dependencies correctly, but if you do not need it at this time, ignoring it should not interfere with its operation.
Now let’s get to work. we need to get Stable Audio Open working on WSL (ubuntu24.04). we will install docker on WSL. we need to install the NVIDIA Container Toolkit (NVIDIA Container Toolkit). Also install the NVIDIA Container Toolkit (if you are using a GPU).
Clone the Docker version of Stable Audio Open on your own computer.
git clone https://github.com/SaladTechnologies/stable-audio-open.gitGo to the created directory
cd stable-audio-open Do the following to realize it locally
Edit hello-gradio.py.
Uncomment demo.launch(server_name=”0.0.0.0″, server_port=8000). Conversely, demo.launch(server_name=”[::]”, server_port=8000) is treated as a comment.
Rewrite the above Dockerfile as needed.

Build the Docker image.
docker image build -t sao1 -f Dockerfile . To leave the image on the host and not have to download the image again after the container is removed, simply remove the -rm option. This will ensure that the image remains on the host even if the container is stopped.
The following is the modified command. You will need to get a token with Hugging Face here. In addition, you must have signed up and logged in at the Stable Audio Open page. There are several models and resources on the Hugging Face platform that require users to register.
Where to get a token

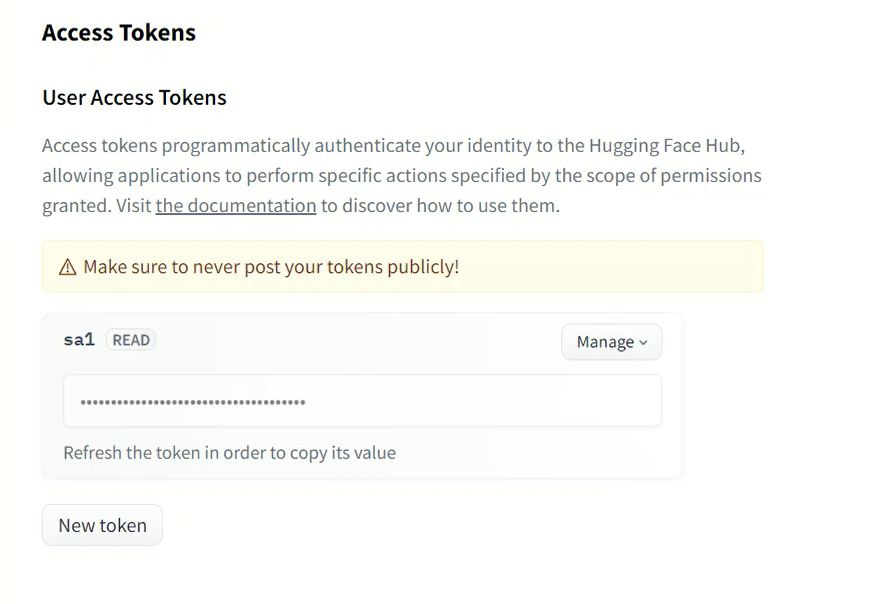
Where to sign up

Once you have done the above, you can launch the container.
The modified command
docker run -it -p 8000:8000 --gpus all -e HF_TOKEN="YOUR_HUGGINGFACE_ACCESS_TOKEN_READ" YOUR_IMAGE_NAMENow, when the container is stopped, the image will remain on the host and will not need to be downloaded again.
Image and Container Management
In addition, for frequent use, it is convenient to create containers with names so that they can be restarted after being stopped.
To create and start a container
docker run -it --name my_stable_audio_container -p 8000:8000 --gpus all -e HF_TOKEN="YOUR_HUGGINGFACE_ACCESS_TOKEN_READ" YOUR_IMAGE_NAMEStopping Containers
To stop the container, execute the following command from another terminal Or you can stop the container by pressing CTRL C in the terminal where it is running interactively. This is especially useful if you are running the container using the -it flag.
docker stop my_stable_audio_containerRestarting a Container
To restart a stopped container, run the following command
docker start -ai my_stable_audio_container About the options of docker start -ai.
- –
ais the short form of--attach, which attaches to the container’s standard output and standard error output. - –
iis shorthand for--interactive, which starts the container interactively and leaves stdin open.
This way, if the container is stopped, it is not deleted and can be restarted and reused. Combined, these methods allow for efficient container and image management.
When you start the container, you should see something like the following.
/opt/conda/lib/python3.10/site-packages/torch/nn/utils/weight_norm.py:28: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.weight_norm UserWarning: torch.nn.utils.parametrizations.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn(“torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.”)
Running on local URL: http://0.0.0.0:8000
If you are running on WSL, the address 0.0.0.0:8000 points to a local address in the container; you need to get the WSL IP address and access it with the correct URL.
Verifying the WSL ‘s IP address Verify the WSL’s IP address in the terminal using the ip a command.
ip a One of the network interfaces of the WSL has an IP address starting with inet. For example, you may get the following output
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:15:5d:43:a4:7b brd ff:ff:ff:ff:ff:ff
inet 172.25.209.126/20 brd 172.25.223.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::215:5dff:fe43:a47b/64 scope link
valid_lft forever preferred_lft forever Access with a browser Access with a browser using the obtained IP address. For example, if the IP address is 172.25.209.126, access as follows
http://172.25.209.126:8000