
Troubleshooting seed-vc After a Major Version Update: CUDA 121 to 126 Migration Guide
Voice conversion technology has been evolving rapidly, and the open-source seed-vc project is no exception. If you’ve recently pulled the latest updates from the seed-vc GitHub repository, you might have encountered compatibility issues due to the transition from CUDA 12.1 to CUDA 12.6. This comprehensive guide will walk you through the exact steps needed to resolve these issues and get your voice conversion models working flawlessly again.
If you’re new to seed-vc, you might want to first check my previous guides:
Prerequisites: Understanding the CUDA Update Challenge
For Windows users with CUDA 12.8 drivers installed (which are backward compatible with CUDA 12.6 builds), the recent changes to the project’s requirements.txt file have introduced significant compatibility challenges. When running git pull, you’ll notice the following critical change:
torch --pre --index-url https://download.pytorch.org/whl/nightly/cu126
This indicates a migration from the previous cu121 build to the newer cu126 build, which can break your existing Python virtual environment’s compatibility.
Why You Need to Recreate Your Virtual Environment
When Python virtual environments have previously installed PyTorch libraries with specific CUDA dependencies, simply updating your requirements can lead to conflicts. Here’s why a complete reset is often necessary:
The Hidden Compatibility Challenge
Python virtual environments cache installed libraries, including their specific builds and dependencies. In your existing environment, you likely have PyTorch libraries built for CUDA 12.1 already installed. When attempting to introduce CUDA 12.6 dependencies, these conflicting builds can cause several issues:
- Running
pip install -r requirements.txtmay fail to properly resolve the dependency conflicts - Even if the installation completes, you might encounter runtime errors like “Torch not compiled with CUDA enabled”
- The existing environment may silently use cached versions of libraries rather than installing the ones you actually need
Completely removing and recreating the virtual environment is the most reliable solution to ensure a clean dependency tree without conflicts.
Step-by-Step: Deleting Your Virtual Environment
Method 1: Using the Terminal (Recommended for Experienced Users)
rm -rf .venvFor PowerShell users, the equivalent command is:
Remove-Item -Recurse -Force .venvMethod 2: Using GUI Tools (Beginner-Friendly)
- In VSCode: Find the
.venvfolder in the Explorer panel, right-click, and select “Delete” - In Windows Explorer: Navigate to your project folder and delete the
.venvdirectory
This completely removes all cached dependencies and ensures a fresh start for your environment.
Why Windows Users Face Unique Challenges
Interestingly, these compatibility issues are often more pronounced on Windows systems compared to Linux or WSL (Windows Subsystem for Linux) environments. In my practical testing, I’ve observed that WSL environments sometimes handle CUDA version changes more gracefully, allowing the same virtual environment to continue functioning after a PyTorch CUDA version update.
Technical Reasons for Windows-Specific Problems
Windows environments tend to create stronger bindings between installed PyTorch packages and specific CUDA versions. This leads to several potential issues:
- Previously cached CUDA 12.1 PyTorch versions may remain and take precedence
- Dependency resolution can fail due to conflicts between packages
- Runtime errors like “Torch not compiled with CUDA enabled” frequently occur
These problems necessitate a more thorough approach to dependency management on Windows.
Essential Requirements.txt Modifications
After recreating your virtual environment, you’ll need to modify the requirements.txt file to ensure proper compatibility. Here’s the optimized configuration I developed through practical testing:
--extra-index-url https://download.pytorch.org/whl/nightly/cu126
# PyTorch Nightly CUDA 12.6 builds
torch --pre
torchvision --pre
torchaudio --pre
# Other dependencies
scipy==1.13.1
librosa==0.10.2
huggingface-hub==0.28.1 # ✅ Compatible with gradio
# accelerate removed (add later if needed)
munch==4.0.0
einops==0.8.0
descript-audio-codec==1.0.0
gradio==5.23.0
pydub==0.25.1
resemblyzer
jiwer==3.0.3
transformers==4.38.2
FreeSimpleGUI==5.1.1
soundfile==0.12.1
sounddevice==0.5.0
modelscope==1.18.1
funasr==1.1.5
numpy==1.26.4
hydra-core==1.3.2
pyyaml
python-dotenv
The Technical Rationale Behind These Requirements Modifications
These specific changes to the requirements file address several critical compatibility issues:
Adding the PyTorch Nightly Repository Source
--extra-index-url https://download.pytorch.org/whl/nightly/cu126
CUDA 12.6-compatible PyTorch builds aren’t hosted on the standard PyPI repository but are distributed through a specialized index. By explicitly adding this index URL, we ensure pip knows where to find the appropriate CUDA-enabled versions.
Enabling Pre-release Builds with --pre
The torch --pre specification enables access to nightly (development) builds that contain the latest CUDA compatibility features. These nightly builds include CUDA 12.6 support that hasn’t yet been released in stable versions but is crucial for our needs.
Resolving HuggingFace and Gradio Version Conflicts
One of the most subtle compatibility issues involves the relationship between different libraries:
- Gradio 5.23.0 requires huggingface-hub version 0.28.1 or higher
- Meanwhile, the older accelerate package requires huggingface-hub below version 0.28
This creates an irreconcilable conflict that prevents both packages from working simultaneously. My solution removes accelerate (which can be added back later if essential) and standardizes on huggingface-hub 0.28.1 to maintain gradio compatibility.
Fast-Track Method: One-Command PyTorch Installation
For those who prefer a streamlined approach without modifying requirements.txt, here’s a direct installation command that bypasses potential dependency conflicts:
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu126This single command accomplishes several things simultaneously:
- Installs the PyTorch nightly (development) builds
- Explicitly targets CUDA 12.6 compatible binaries
- Avoids requirements.txt dependency resolution conflicts
This approach is particularly useful when you encounter stubborn installation issues or want a clean, focused installation of just the PyTorch components.
Verifying Your Installation Success
After installing the PyTorch packages, it’s essential to verify that CUDA support is properly enabled. Run this simple Python command to check:
python -c "import torch; print(torch.version.cuda); print(torch.cuda.is_available())"
What Success Looks Like
If your installation was successful, you should see output similar to:
12.6
True
This confirms that:
- PyTorch recognizes your CUDA installation (version 12.6)
- CUDA functionality is properly available to PyTorch
Troubleshooting Failed Installations
If instead you see:
None
False
This indicates PyTorch is only running in CPU mode without CUDA acceleration. The most common causes include:
- Installing the CPU-only version of PyTorch by mistake
- Package conflicts during installation
- Incorrect CUDA paths or driver issues
In this case, I recommend running the direct installation command mentioned earlier:
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu126Why Installation Order Matters
When working with complex requirements files, the installation sequence can significantly impact dependency resolution:
- If PyTorch is installed as part of a large requirements batch, pip’s dependency resolver might select the wrong version
- Explicitly specified versions like
torch==2.4.0might default to CPU-only versions from PyPI - Installing CUDA-enabled PyTorch separately and first ensures it takes precedence in dependency resolution
This workflow is particularly important for Windows users, where PyTorch CUDA dependencies tend to be more sensitive than on Linux systems.
Launching the Web UI and Using the GUI Interface
Once you’ve successfully configured your virtual environment and installed all dependencies, it’s time to launch the application. seed-vc provides a browser-based graphical interface that makes voice conversion accessible and intuitive.
Starting the V2 Model (Latest Feature-Rich Version)
To launch the advanced V2 model interface, run:
python app_vc_v2.pyAfter execution, you’ll see a message in your terminal similar to:
* Running on local URL: http://127.0.0.1:7860
Opening this URL (http://127.0.0.1:7860) in your browser will display the GUI interface, where you can drag and drop audio files, adjust parameters, and perform voice conversions with ease.
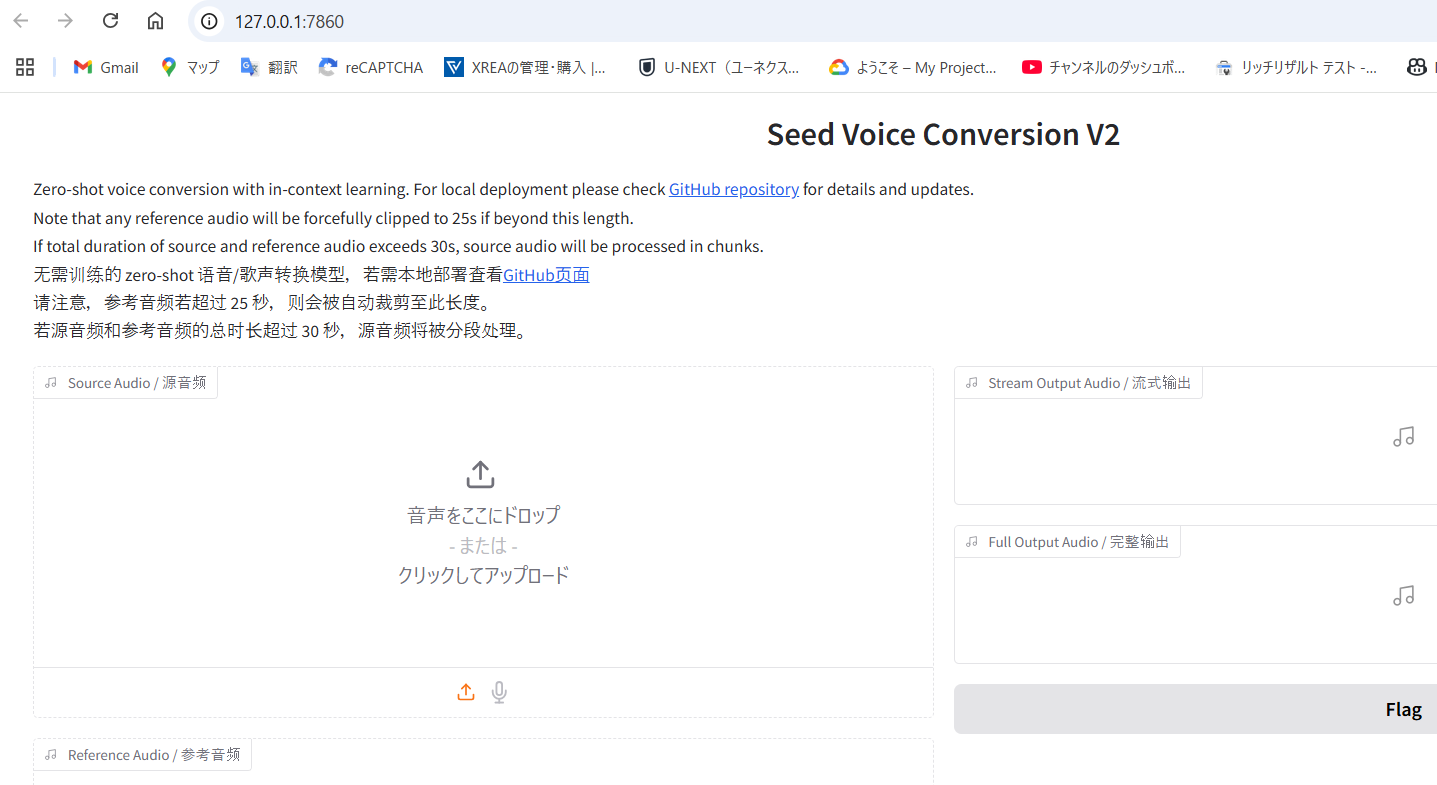
Why Choose the V2 Model?
According to official documentation, the V2 model (app_vc_v2.py) offers several advanced capabilities:
- More natural speaker anonymization capabilities
- Enhanced accent and speech pattern conversion
- Higher-precision conversion using AR (autoregressive) models
- Rich parameterization options to control inference quality (e.g.,
--similarity-cfg-rate,--intelligibility-cfg-rate, and more)
While I initially chose V2 expecting superior functionality, I discovered through practical testing that it can sometimes be less polished than the standard app.py or app_vc.py implementations. You might encounter occasional errors or fewer configuration options in some areas.
Nevertheless, the zero-shot conversion and anonymization features make it worth exploring, especially for advanced users looking to push the boundaries of voice conversion technology.
Practical GUI Usage Guide
The Web interface allows for intuitive operation:
- Upload Source Audio – Add the original voice recording you want to convert
- Upload Reference Audio – Provide a sample of the target voice to extract characteristic features
- Adjust Parameters – Fine-tune voice quality, smoothness, pitch preservation, and other aspects
- Generate Conversion – Click the convert button to process the audio using the selected parameters
For a visual demonstration of this workflow, check out my tutorial video:
