
What is Seed-VC?
According to the description on GitHub, Seed-VC is a zero-shot voice changer and singing voice conversion tool that can clone a voice using a 1–30 second voice sample without any training. The current model delivers higher voice clarity and speaker similarity compared to previous voice conversion models.

In evaluations using voice data from the LibriTTS dataset, Seed-VC outshined two baseline models (OpenVoice and CosyVoice) in both clarity (intelligibility) and speaker similarity.
In a nutshell, Seed-VC showcases superior performance in voice conversion and cloning technology when stacked up against other models.
Today, we’ll be walking you through the process of installing Seed-VC on a Windows PC. Before we jump into the installation, I’ll give you a rundown on how Seed-VC is evaluated. Now, the number of commands might seem a bit daunting for beginners. That’s why I propose using Gradio to execute it via a GUI (Graphical User Interface), which should make it more approachable. But don’t worry, I’ll also be explaining the evaluation and usage methods for those who prefer the command line.
Evaluation Method of Seed-VC
Seed-VC employs various techniques and models to assess the quality of voice conversion results. Specifically, it has been shown to outperform other non-zero-shot models (such as those pre-trained on specific speakers) in terms of generating superior output.
What is a Zero-Shot Model?
Typically, voice conversion models are pre-trained on specific speakers’ voices. However, zero-shot models don’t require any training and can clone or convert the voices of speakers they are hearing for the first time. Seed-VC is one such zero-shot conversion model.
Comparison with SoVITS Models
Seed-VC is compared to other voice conversion models, such as SoVITS. Specific models like “Tokai Teio,” “Matikane Tannhäuser,” and “Milky Green” are mentioned, which are commonly used in the field of voice conversion.
How to Reproduce the Evaluation
You can reproduce the evaluation yourself using the provided eval.py script. The evaluation uses tools like Facebook’s Hubert model and Resemblyzer to assess the quality of the voice conversion results.
How to Run eval.py (Steps for Reproducing the Evaluation)
You can replicate the evaluation of Seed-VC’s voice conversion using eval.py. Below are the steps:
python eval.py
--source ./examples/libritts-test-clean
--target ./examples/reference
--output ./examples/eval/converted
--diffusion-steps 25
--length-adjust 1.0
--inference-cfg-rate 0.7
--xvector-extractor "resemblyzer"
--baseline "" # Fill in if you want to use OpenVoice or CosyVoice
--max-samples 100 # Evaluate with up to 100 samples
Explanation of Each Option:
source: The original audio file to be converted.target: The target voice audio file used for reference.output: The directory where the conversion result will be saved.diffusion-steps: The number of steps that affect the accuracy of the voice conversion. More steps result in better quality but increase processing time.length-adjust: Adjusts the length of the audio. 1.0 keeps the original length; use <1.0 for shorter and >1.0 for longer audio.xvector-extractor: The model used for speaker feature extraction (Resemblyzer).baseline: Allows comparison with other models (OpenVoice or CosyVoice).
Usage Instructions
This section explains how to use Seed-VC to perform actual voice conversion, particularly how to convert voices using the command line.
Steps for Voice Conversion via Command Line:
python inference.py --source <source-wav>
--target <reference-wav>
--output <output-dir>
--diffusion-steps 25 # 25 steps for voice conversion; 50–100 steps recommended for singing voice conversion
--length-adjust 1.0
--inference-cfg-rate 0.7
--f0-condition False # Set to True for singing voice conversion
--auto-f0-adjust False # Normally set to False, but use True for automatic pitch adjustment
--semi-tone-shift 0 # Adjust pitch in semitone units, if needed
Explanation of Each Option:
source: The original audio file to be converted.target: The target voice audio file used for reference (target voice).output: The folder where the results will be saved.diffusion-steps: The number of steps that determine the accuracy of the voice conversion. 25 is standard; 50–100 steps are recommended for singing voice conversion.length-adjust: An option to adjust the length of the audio. The default is 1.0 for no adjustment. Use <1.0 to speed up the audio, and >1.0 to slow it down.inference-cfg-rate: An option used for fine-tuning the output results. The default is 0.7.f0-condition: Specifies whether to match the pitch of the output to the original audio. Use True for singing voice conversion.auto-f0-adjust: An option to automatically adjust the pitch from the original to match the target voice (usually not used for singing voice conversion).semi-tone-shift: An option to adjust pitch in semitone increments. Use this option when adjusting the pitch of the audio during singing voice conversion.
Installation Steps
This will be explained later, but it is necessary to install the required packages using pip install -r requirements.txt for both command-line and Gradio usage. Python 3.10 is recommended.
This guide covers Seed-VC’s evaluation methods and actual voice conversion usage. Using the evaluation steps, you can check the quality of voice conversion while comparing it to other models. When running the project, make sure to properly set the specified options to convert voices.
For those who find command-line usage difficult, I will also introduce a method to run Gradio. Gradio makes it easy to try out voice conversion through a web browser, making it very beginner-friendly.
Brief Explanation of Gradio
Gradio is a tool that allows you to easily publish Python code as a web application. With Gradio, Seed-VC’s voice conversion functionality can be run without memorizing commands or using the terminal. Below, I will show how to run it with Gradio.
How to Clone the Git Repository
Cloning a Git repository means copying the files and code of a project from the internet to your computer. Many projects are available on GitHub, and Seed-VC is one of them.
First, use the following command:
git clone https://github.com/Plachtaa/seed-vc.gitExplanation of the Command:
git: This is the command for using Git, a version control tool.clone: This command tells Git to copy (clone) the repository.https://github.com/Plachtaa/seed-vc.git: This is the URL of the repository you want to clone. A repository is where all the project’s files and its change history are stored.
When you run this command, the Seed-VC project will be downloaded to your computer, and a folder named “seed-vc” will be created in your current working directory.
Steps:
- Open the command line (PowerShell or Command Prompt on Windows, Terminal on macOS or Linux).
- Enter the command above and press Enter.
This will copy the Seed-VC code to your computer. In fact, using VS Code is the most convenient and user-friendly option.
About the Python Version: Python 3.10 is Required
To run Seed-VC, you need a programming language called Python. This is mentioned on the GitHub page. Python is very versatile and is used in many projects, but behavior can vary between versions.
What Does “Suggested Python 3.10” Mean?
For the Seed-VC project, Python 3.10 is recommended. This means it’s optimal to run Seed-VC with Python version 3.10, and using other versions may cause errors. If you have a different version, you can use pyenv instead of reinstalling Python.

Steps to Install Python:
If you don’t have Python 3.10 installed, don’t worry! Here’s a step-by-step guide for beginners:
- Head over to the official Python website (https://www.python.org/).
- Download the installer that matches your operating system (Windows, macOS, or Linux).
- When you run the installer, keep an eye out for the “Add Python 3.x to PATH” checkbox. Make sure to tick this box – it’ll make using Python a breeze later on.
- Once the installation is complete, open up your command line (PowerShell or Command Prompt on Windows, Terminal on macOS or Linux) and type in the following command to double-check that Python 3.10 is installed correctly:
python --versionIf you see “Python 3.10.x” displayed, give yourself a pat on the back – you’ve successfully installed Python!
Setting Up the Seed-VC Project
Now that you’ve cloned the repository and have Python 3.10 ready to go, the next step is to install all the necessary packages listed in the requirements.txt file.
Explanation of the requirements.txt File
The requirements.txt file contains a list of all the packages needed for the Seed-VC project. Let’s take a closer look at what each of these packages does:
--extra-index-url https://download.pytorch.org/whl/cu113
torch
torchvision
torchaudio
scipy==1.13.1
librosa==0.10.2
huggingface-hub
munch
einops
descript-audio-codec
git+https://github.com/openai/whisper.git
gradio
pydub
resemblyzer
jiwer
transformers
onnxruntime
Package Descriptions:
--extra-index-url: This is the URL to download a specific version of PyTorch, a machine learning and deep learning framework used for Seed-VC’s voice conversion feature.torch,torchvision,torchaudio: These are packages related to PyTorch, supporting audio and image processing.scipy,librosa: Used for scientific computing and audio analysis.huggingface-hub,transformers: Hugging Face packages, famous for natural language processing (NLP), used for managing and running machine learning models.munch,einops,descript-audio-codec: Packages used for data manipulation and conversion.git+https://github.com/openai/whisper.git: This fetches the library directly from OpenAI’s Whisper project, which provides speech recognition functionality.gradio: A tool that allows you to easily create web interfaces. It is used to make Seed-VC’s demo and operations easier.pydub: A package used for manipulating audio files.resemblyzer,jiwer: Used for evaluating speaker similarity and speech recognition results.onnxruntime: A tool to efficiently run machine learning models.
Steps to Install the Packages Using requirements.txt
Now that we know what each package does, let’s dive into how to install them using the requirements.txt file.
Steps:
- Create a Python Virtual Environment (Recommended)
By using a virtual environment, you can install different Python versions and libraries for each project, preventing conflicts between projects. This keeps your computer organized. To create a virtual environment, use the following command:
python -m venv venvThis creates a virtual environment named venv in your project folder.
- Activate the Virtual Environment
To activate the virtual environment, use the following commands:
- For Windows:
.\venv\Scripts\activate(In VS Code,venv\Scripts\activateworks as well) - For macOS/Linux:
source venv/bin/activate
Once the virtual environment is activated,(venv)should appear on the left side of your command line prompt.
- Install Packages Using
requirements.txt
With the virtual environment activated, run the following command:
pip install -r requirements.txtThis will automatically install all the packages listed in the requirements.txt file.
Troubleshooting During Installation
If you run into any issues during the installation process, don’t panic! Here are some common problems and how to solve them:
When Errors Occur:
Sometimes, certain packages may fail to install. When this happens, take a closer look at the error message. You might need to install some missing dependencies (like C++ build tools). Installing necessary tools, such as the Visual C++ Build Tools, is often the solution. I’ll go into more detail about the specific errors you might encounter in just a bit.
CUDA-Related Errors:
Some versions of PyTorch use GPUs (CUDA). If CUDA isn’t available in your environment, you might need to install a different version of PyTorch (one that’s designed for CPU use). If CUDA isn’t necessary, you can change the URL in the requirements.txt file like this (I tested it, but it ran much slower):
--extra-index-url https://download.pytorch.org/whl/cpuConclusion
Phew! That was a lot of information, but you’re almost there. With all the necessary libraries installed using the requirements.txt file, you’re ready to start running the Seed-VC project. In the next section, we’ll dive into how to actually run the project and start converting voices like a pro!
Actual Error Encountered
DEPRECATION: webrtcvad is being installed using the legacy 'setup.py install' method, because it does not have a 'pyproject.toml' and the 'wheel' package is not installed. pip 23.1 will enforce this behaviour change. A possible replacement is to enable the '--use-pep517' option. Discussion can be found at https://github.com/pypa/pip/issues/8559
Running setup.py install for webrtcvad ... error
error: subprocess-exited-with-error
× Running setup.py install for webrtcvad did not run successfully.
│ exit code: 1
╰─> [11 lines of output]
running install
C:\youtube\seed-vc\venv\lib\site-packages\setuptools\command\install.py:34: SetuptoolsDeprecationWarning: setup.py install is deprecated. Use build and pip and other standards-based tools.
warnings.warn(
running build
running build_py
creating build
creating build\lib.win-amd64-cpython-310
copying webrtcvad.py -> build\lib.win-amd64-cpython-310
running build_ext
building '_webrtcvad' extension
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: legacy-install-failure
× Encountered error while trying to install package.
╰─> webrtcvad
note: This is an issue with the package mentioned above, not pip.
hint: See above for output from the failure.
[notice] A new release of pip is available: 23.0.1 -> 24.2
[notice] To update, run: python.exe -m pip install --upgrade pip
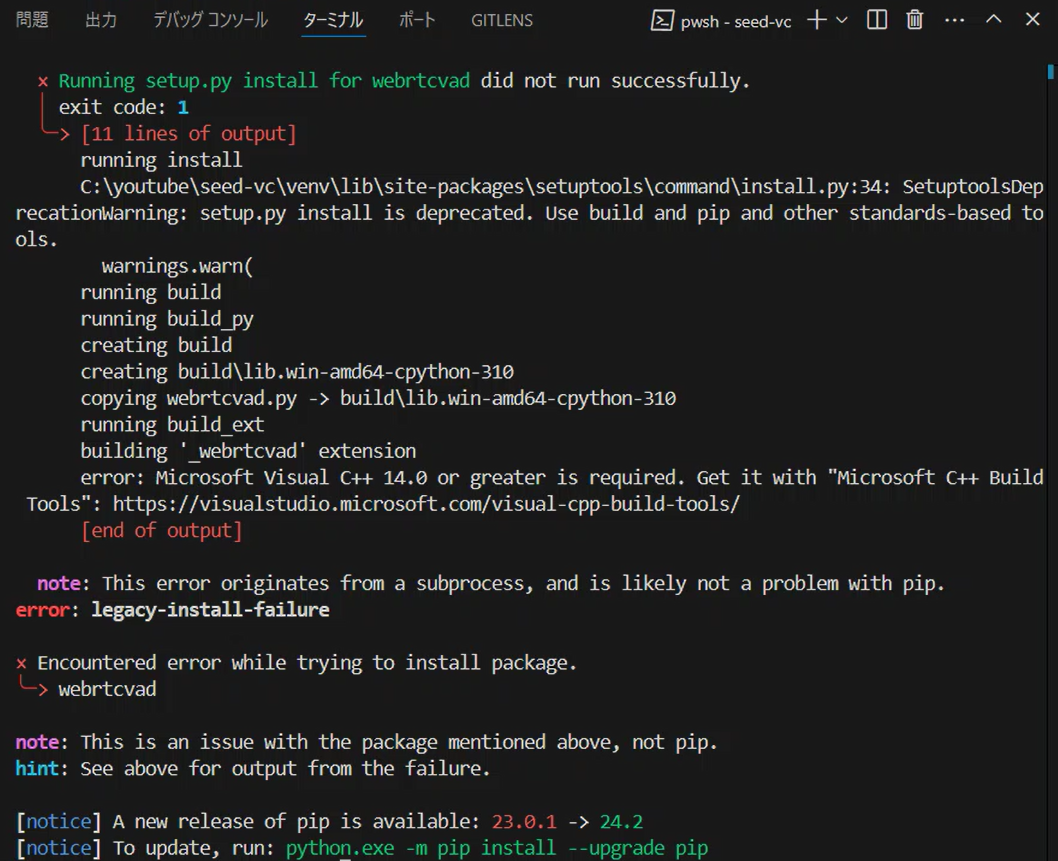
This error message is telling us that the Microsoft Visual C++ Build Tools are required to install the webrtcvad package. Specifically, it suggests that Microsoft Visual C++ 14.0 or higher is not installed on your system, which is likely causing the compilation to fail.

Solution: Install Microsoft C++ Build Tools
To fix this issue, you’ll need to install the Microsoft C++ Build Tools by following the link provided in the error message. Here’s what you need to do:
- Head over to the Microsoft C++ Build Tools website and download the installer.
- Run the installer and select the “Desktop development with C++” workload for installation. This will include Visual C++ 14.0 and other necessary tools.
Even if you’re using VS Code, some packages listed in the requirements.txt file, such as torch and webrtcvad, may require compilation. That’s where the Microsoft C++ Build Tools come in handy.
Why Are Microsoft C++ Build Tools Necessary?
Certain Python libraries have parts written in C++, and these need to be compiled during installation. On Windows, the Microsoft C++ Build Tools are required to handle this compilation process.
For the Seed-VC project, several packages (like torch and webrtcvad) fall into this category, so installing the C++ Build Tools is highly recommended.
Upgrading pip (Recommended):
Additionally, the error message might indicate that a newer version of pip is available. It’s a good idea to upgrade pip using the following command:
python.exe -m pip install --upgrade pipDuring the Microsoft C++ Build Tools installation, you only need to install the minimum components required to compile the necessary Python packages. Let me walk you through the specific items you should select.
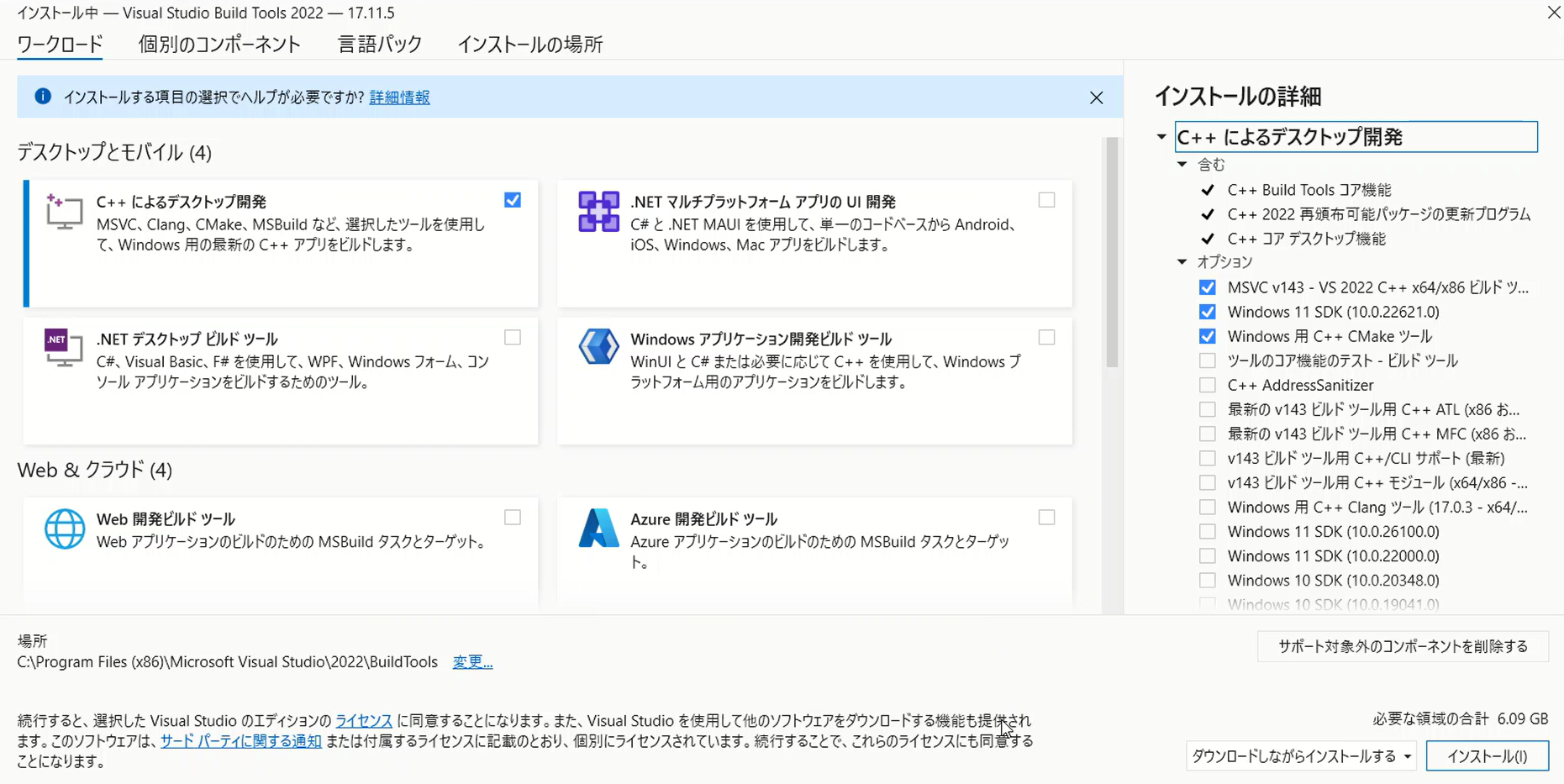
Desktop development with C++
The most important selection is “Desktop development with C++”. Make sure to check this option.
Reason for this selection:
This workload includes the Microsoft Visual C++ compiler and related tools necessary for compiling Python packages.
Additional Components
When you select “Desktop development with C++”, several options are automatically selected. Here, I’ll explain the minimum recommended setup for beginners. Make sure the following components are checked during the installation process:
Essential Items (Usually Selected Automatically):
- MSVC v143 – VS 2022 C++ x64/x86 build tools (or the latest version)
This is the C++ build tool for Visual Studio, which is required to compile Python packages. - Windows 11 SDK
Includes libraries and header files needed for development on Windows. - C++ CMake tools for Windows
CMake is a tool used to manage the build process, which may be required for compiling Python packages.
Let me also explain the automatically selected items:
- Core Tools for Testing
- Explanation: This tool is for testing applications in Visual Studio.
- Necessity: It’s not directly related to Seed-VC or Python package installation, so it’s optional, but there’s no harm in installing it.
- C++ Address Sanitizer
- Explanation: This tool detects memory-related errors.
- Necessity: Not necessary for installing Python packages. It’s a tool for advanced C++ development, and it’s not required for using Seed-VC.
Recommendation:
These automatically selected tools are not essential, and you can uncheck them if you don’t need them. As long as “Desktop development with C++”, the MSVC compiler, the Windows SDK, and CMake are installed, you’ll have the environment needed to compile Python packages.
For a minimal setup, you can organize the selection like this:
- Windows 11 SDK: Required
- Core Tools for Testing: Optional (Uncheck if unnecessary)
- C++ Address Sanitizer: Optional (Uncheck if unnecessary)
This will provide the minimal required environment.
Start the Installation
Once you’ve made these selections, click the “Install” button. The installation may take some time, but after it’s done, the compilation errors you encountered during Python package installation should be resolved.
Post-Installation Check
After the installation is complete, rerun the following command to install the necessary packages:
pip install -r requirements.txtThis should resolve the Visual C++ Build Tools error, and the required packages for the Seed-VC project should install successfully.
Note:
Microsoft C++ Build Tools errors typically occur only in Windows environments. These tools are specific to Windows for compiling C++ code. Therefore, you won’t encounter such errors in WSL (Windows Subsystem for Linux) or Linux environments.
Compilation Errors in WSL and Linux Environments
However, in WSL and Linux, if there are required C++ packages or libraries, you’ll need to install the corresponding development tools. For example, when installing some Python packages (such as torch), the following development tools may be required on Linux.
Command to Install Necessary Tools (for Linux/WSL):
sudo apt update
sudo apt install build-essentialbuild-essential includes a C++ compiler (g++) and other development tools, providing the environment necessary for compiling C++ code.
Additionally, the following tools may also be required:
sudo apt install libssl-dev libffi-dev python3-dev- On Windows, Microsoft C++ Build Tools are required for C++ compilation.
- In WSL and Linux, development tools like
build-essentialare needed, but Microsoft C++ Build Tools are not necessary.
With the appropriate development tools installed on WSL or Linux, C++-related errors can be avoided.
build-essential in WSL and Linux environments is equivalent to Microsoft’s C++ Build Tools on Windows. It includes essential tools such as C and C++ compilers (gcc and g++), Makefile support, and other necessary components for compilation. With these installed, the environment needed to build Python packages or C++ libraries is complete.
- On Windows, Microsoft C++ Build Tools are needed to compile C++ libraries.
- On WSL and Linux,
build-essentialprovides the necessary tools to compile C++ libraries.
In other words, by installing build-essential, you can set up the development environment needed on Linux or WSL.
Next, you will launch the browser-based version. It should launch with the following command:
python app.pyThis script prepares for voice conversion by downloading several different models and configuring them.
Specifically, the flow is as follows:
Model Downloads:
Using a function called load_custom_model_from_hf, multiple models are downloaded from Hugging Face (HF). For example, the following models are downloaded:
- Plachta/Seed-VC: A model for voice conversion.
- funasr/campplus: A model used for extracting voice style.
- nvidia/bigvgan_v2_22khz_80band_256x: A high-quality voice generation model using BigVGAN.
- lj1995/VoiceConversionWebUI: A model for F0 (fundamental frequency) estimation.
- openai/whisper-small: A Whisper model for voice processing.
Loading and Configuring Models:
Each model is loaded and configured. The torch.device is used to determine the hardware (GPU or CPU) and initialize the parameters of each model.
Executing Voice Conversion:
A function called voice_conversion is defined to perform actual voice conversion. Through Gradio, users can upload an audio file via the web browser, adjust settings, and execute the voice conversion.
This script automatically downloads the required voice conversion models and auxiliary models from Hugging Face and configures them. The downloaded models are used for voice conversion, high-quality voice generation, and F0 adjustment. Then, using Gradio, users can easily perform voice conversion through a web browser.
Next, try accessing the browser:
http://127.0.0.1:7860/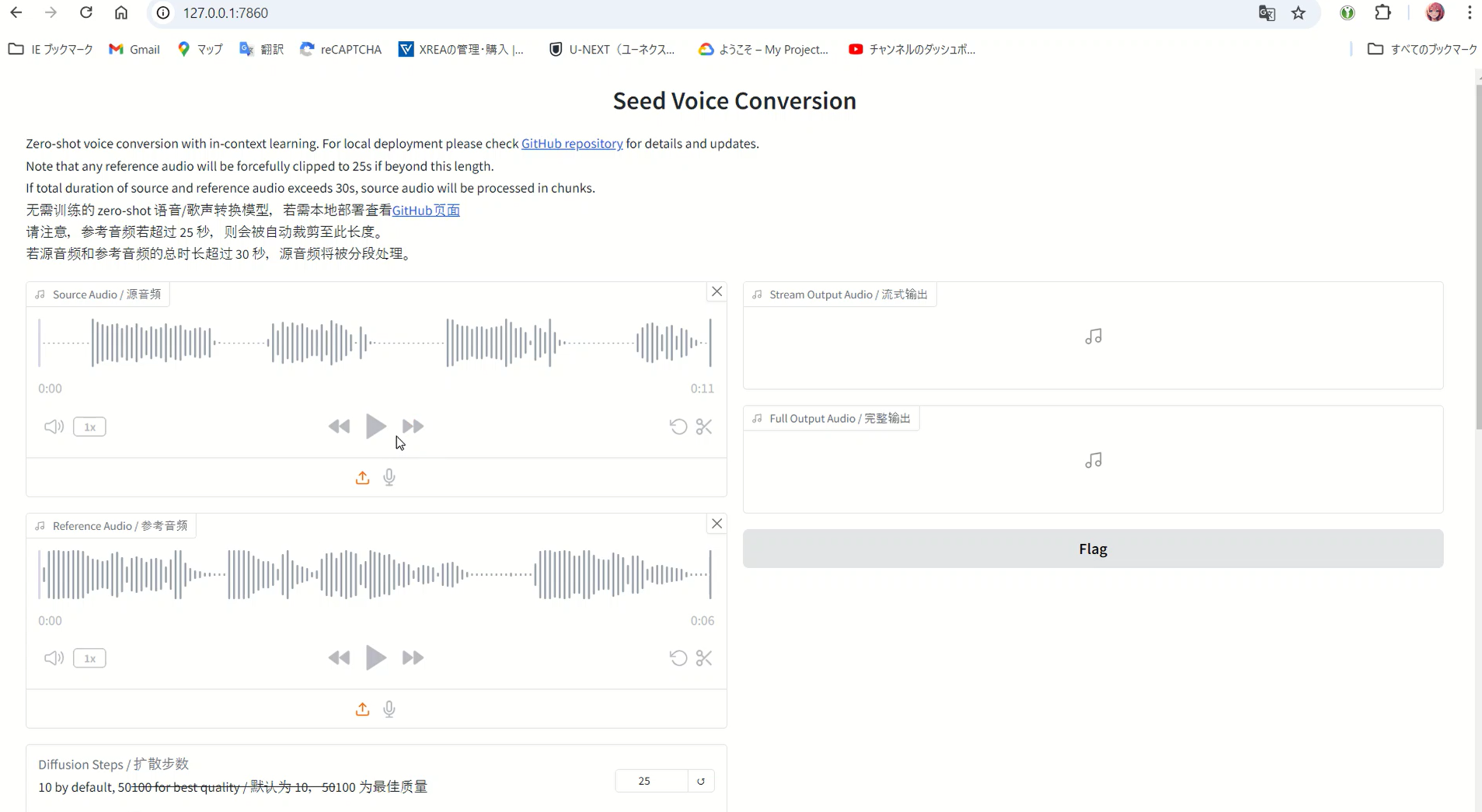
How to Use the Tool
The key step is to upload the voice you want to clone into the “Reference Audio” field, and the voice you want to mimic it to in the “Source Audio” field. Once the creation is successful, a clone will be generated with the sound quality of the audio in the “Reference Audio” field. However, despite using the GPU, the creation process was very slow, so I investigated the issue. First, check the CUDA version installed on the PC.
nvcc --versionThe output was as follows:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Thu_Mar_28_02:30:10_Pacific_Daylight_Time_2024
Cuda compilation tools, release 12.4, V12.4.131
Build cuda_12.4.r12.4/compiler.34097967_0
Upon checking the current environment, CUDA 12.4 was installed, meaning the PyTorch version specified for CUDA 11.3 (cu113) in the --extra-index-url may not be compatible.
When I checked the following page, CUDA 12.4 was displayed as the latest version at the time:

If the PyTorch and CUDA versions do not match, it can cause performance issues. If you are using CUDA 12.4, you need to install the version of PyTorch that corresponds to it.
Solution: Install PyTorch for CUDA 12.4
To do this, you need to modify the requirements.txt file. In requirements.txt, change the --extra-index-url line as follows:
--extra-index-url https://download.pytorch.org/whl/cu124Next, delete the old virtual environment by simply removing the venv folder. After that, follow the same installation steps again. The speed increased significantly.
Below is a more detailed explanation of why the speed “increased dramatically” after following the steps mentioned.
Difference Between GPU and CPU
First, the GPU (the processor on the graphics card) excels at processing large amounts of data in parallel. In contrast, while the CPU is well-suited for general processing, it is not as strong in parallel processing. Tasks like voice conversion and deep learning involve processing large amounts of data, and using a GPU can handle these tasks much faster.
What is CUDA?
CUDA (Compute Unified Device Architecture) is a technology provided by NVIDIA that accelerates general-purpose computing using the GPU. PyTorch utilizes CUDA to maximize GPU performance and significantly increase processing speed.
However, if the PyTorch and CUDA versions do not match, the GPU cannot be used efficiently, resulting in slower processing. Since the initially installed PyTorch was compatible with CUDA 11.3, it could not effectively utilize the CUDA 12.4 installed on this PC, leading to decreased processing speed.
The Importance of Installing the Correct Version
By modifying requirements.txt and installing PyTorch for CUDA 12.4, the GPU could now be fully utilized, significantly increasing processing speed. This is because installing the correct version of PyTorch that corresponds to the CUDA version allows the GPU to work optimally, enabling tasks to be completed quickly through parallel processing.
Specific Example of Speed Improvement
For example, using only the CPU, voice conversion tasks that took several minutes to tens of minutes can be completed in just a few seconds with the GPU. The power of the GPU allows the same tasks to be completed many times faster.
The initially installed PyTorch for CUDA 11.3 was not compatible with the CUDA 12.4 installed on the PC, preventing the GPU from being fully utilized, which slowed down processing. However, after switching to PyTorch for CUDA 12.4, the GPU was fully utilized, leading to a significant improvement in task speed.
Following these steps allows you to execute heavy tasks like deep learning or voice conversion much faster.
The Relationship Between Seed-VC and VALL-E X
The developer of Seed-VC is also the developer of VALL-E X, a well-known project in the field of voice conversion. While VALL-E X is recognized as a highly performant model, Seed-VC was released afterward. It is unclear whether Seed-VC has improved performance compared to VALL-E X, but being the more recent release, it may have incorporated further enhancements. From my experience, I feel the performance has indeed improved.
Differences Between Seed-VC and VALL-E X
Seed-VC and VALL-E X are both related to voice conversion technologies, but they take different approaches.
- Seed-VC: This technology performs voice-to-voice conversion. It can transform the voice of one speaker into another’s. For example, you can input one voice and convert it into the voice of a different speaker.
- VALL-E X: On the other hand, VALL-E X is a technology that generates speech from text. It can generate natural-sounding speech in the voice of a specific speaker based on the input text. Unlike Seed-VC, which deals with voice input, VALL-E X outputs realistic speech from text, using a different set of techniques.
Both were developed by the same creator but specialize in different objectives—voice conversion and speech generation—each excelling in its respective field.


Suggestions for CPU Optimization
To achieve optimal performance on a CPU, the following challenges need to be addressed:
Utilizing Parallel Processing:
While torch.set_num_threads(os.cpu_count()) is already implemented, adding torch.set_num_interop_threads(1) could further improve the efficiency of parallel processing.
Model Quantization:
Quantizing the model to int8 can reduce memory usage and increase inference speed.
Example:
model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)JIT Compilation:
Using PyTorch’s Just-In-Time (JIT) compiler can compile the model and improve execution speed.
Example:
model = torch.jit.script(model)Batch Processing Optimization:
If possible, implementing batch processing to handle multiple samples simultaneously can improve overall throughput.
Improving Memory Efficiency:
Actively removing unnecessary tensors and using torch.cuda.empty_cache() (for GPU memory) can help free memory. While this applies to GPUs, attention should also be given to managing CPU memory.
Optimizing Data Types:
When possible, using float16 instead of float32 can reduce memory usage and improve computational speed.
Using Asynchronous Processing:
Performing I/O operations (such as file reads and writes) asynchronously can reduce CPU idle time.
Profiling and Identifying Bottlenecks:
Using tools like cProfile or line_profiler to analyze code execution time in detail can help identify the parts of the code that take the most time.
Using NumPy:
Where possible, using NumPy instead of PyTorch operations might improve speed for certain computations.
Model Pruning:
Removing non-essential parameters from the model can reduce the model size and improve inference speed.
When applying these optimizations, it’s important to be mindful of the trade-offs with accuracy and to test performance after each change.
Note (CUDA 12.6)
Seed-VC has undergone a major upgrade and now supports CUDA 12.6. After running git pull to update the repository, the project no longer worked as before. This article has been updated to reflect the latest changes and provide a working setup.

